
![[AI安全入门] 通过篡改模型禁用特定类别 | HackTheBox 燃料危机报道](https://hack-lab-256.com/wp-content/uploads/2025/08/hack-lab-256-samnail-32.jpg)
我们现在正处于一个人工智能不再仅仅“学习和决策”的时代,做出这些决策的模型本身也成为攻击的目标。
尤其是机器学习模型的权重和偏差,它们对于确定其输出至关重要,如果这些权重和偏差被篡改,预测结果可能会被故意扭曲。
这些模型操纵攻击(模型操纵/定向错误分类)可被利用来持续错误识别特定类别或规避检测系统。
例如,它可以被用来在监控摄像头或 OCR 身份验证系统中“仅忽略特定人员或车牌”。
在本文中,我们将演示如何通过 HackTheBox CTF 挑战赛 Fuel Crisis 篡改模型的最后一层偏差,并彻底禁用特定类别(数字“2”)。
我们还将讲解在此过程中可以学习的 AI 安全基础知识以及防御要点。
- 电容式非接触式系统独有的清脆打字感觉!
- REALFORCE首款无线兼容设备!有线连接也可用!
- 与 HHKB 不同,日语键盘布局没有任何怪癖,任何人都可以轻松使用!
- 配有拇指轮,水平滚动非常容易!
- 还拥有出色的降噪性能,安静舒适!
- 滚动可以在高速模式和棘轮模式之间切换!
关于 HackTheBox
这次我们其实是HackTheBox(HTB)来验证漏洞。
HackTheBox 是一个实践型 CTF 平台,参赛者可以在各种安全领域进行练习,包括 Web 应用程序、服务器和网络。
其最大的特点是参赛者可以通过实际访问将被攻击的设备和应用程序并亲自动手来学习。
之前在 HackTheBox 上提供的挑战类别目前是VIP 计划或更高级别(请注意,只有免费计划的用户才能参加主动挑战)。
还有各种类别的机器和挑战,包括 Web、逆向、Pwn 和取证,因此您可以根据自己的水平来应对它们。
如果您想认真磨练使用 HackTheBox 的技能,请务必VIP 计划并充分利用过去的机器和挑战。
👉 有关如何注册 HackTheBox 以及各个计划之间的差异的详细信息,请单击此处。

挑战概述:燃料危机
挑战在于,在燃料即将耗尽的情况下,如何让“费尔康”号飞船与被禁止停靠的B1-4S3D空间站对接。
空间站入口处设有两台OCR摄像头,第一台摄像头读取飞船的ID和可靠性,第二台摄像头重新评估并进行比较。如果两个摄像头的结果差异较大,飞船将被拒绝进入。
幸运的是,一位黑客已经控制了第二个摄像头的模型文件上传权限,甚至可以在飞船经过时禁用验证过程。
玩家的任务是利用这种情况,篡改模型的内部参数,使飞船ID中只有数字“2”才能被识别。
观点
- 攻击目标:在空间站第二个OCR摄像头上运行的机器学习模型(Keras/h5格式)
- 目标:始终错误识别数字“2”,并阻止您的船舶ID被正确检测到。
- 方法:将模型最后一层Dense层中“2”类的偏差值设置为一个较大的负数(例如-100)。
- 成功条件:其他舰船(4艘)正确识别,且自身舰船“2”号未被识别,对接成功。
什么是 Keras 和 h5 格式?
在《燃料危机》中,我们直接重写 h5 文件中最终 Dense 层的偏差值,以强制特定类(数字“2”)的输出较低,从而永远不会被识别。
喀拉什
Keras 是一个 Python 的高级深度学习框架。
它是一个库,可以轻松操作 TensorFlow 和 Theano 等后端,并允许您使用直观的 API 构建、训练和保存模型。
在这个 Fuel Crisis 项目中,我们利用 Keras 创建了一个 OCR(字符识别)模型,并分配了预先训练好的权重。
h5格式
.h5 是名为 HDF5(分层数据格式,版本 5)的数据存储格式的扩展名。Keras
可以将训练好的模型及其权重保存为 h5 格式。
此格式具有分层结构,可以按原样存储
权重和偏差虽然在文本编辑器中读取起来比较困难,但您可以使用 h5py 或 HDFView 等工具打开并直接编辑内容。
通过篡改模型使特定类无效意味着什么?
篡改模型以禁用特定类别是一种攻击方法,它重写已训练 AI 模型的内部参数,以确保特定类别永远不会被预测。
例如,在 OCR 或面部识别中,这可能导致特定数字或人物持续被错误识别,从而逃避检测。
这种方法推理阶段,不同于通过直接操纵模型核心来更改输入数据(对抗样本)的攻击。
攻击如何运作
这种攻击的原理是,故意操纵机器学习模型使用内部参数生成的最终类别得分。
具体来说,通过将最后一层(例如 Dense 层)的偏差值设置为一个极负值,该类别的得分将始终较低,并且不再被考虑用于预测。
由于其他参数保持不变,整体行为和可靠性基本保持不变。
- 将偏差值设置为较大的负值→相应的类将始终获得较低的分数
- 其他类别的准确性基本得以维持,因此篡改并不引人注意。
- 在燃料危机中,目标类别是数字“2”
攻击流程
攻击涉及以下步骤:
- 获取训练好的模型文件(.h5格式)
- 用 h5py 或 HDFView 打开内容,并识别最终 Dense 层的“Class 2”对应的偏差值。
- 将偏差值更改为极端负数(例如 -100)
- 将修改后的模型重新上传到系统
- 在推理过程中,包含“2”的 ID 总是被误认为是其他数字,从而避免被发现。
需满足的条件
此次攻击要想成功,需要满足几个先决条件,
如果这些条件不满足,那么即使实施了攻击,也无法达到预期的效果。
- 攻击者可以直接检索和编辑模型文件
- 上传模型时不执行篡改验证(签名或哈希校验)
- 禁用特定类别不会对其他行为产生任何明显的影响。
我确实尝试过破解它!
在深入探讨攻击机制之前,我们先快速浏览一下 Fuel Crisis 的 Web 应用。
该应用的 UI 模拟了空间站的对接门,五艘飞船依次通过。每艘飞船都被分配了一个飞船 ID(一串数字)
屏幕上的主要元素如下:
- 舰船ID显示区:
显示五张舰船ID图片。您的舰船为最后通过的舰船,其ID包含数字“2”。 - 模型文件上传表单:您
可以选择并上传一个 .h5 格式的模型文件。您将在此处上传修改后的模型。 - 对接按钮
将通过OCR模型进行识别,以确定是否可以对接。如果篡改成功,则只有您自己的飞船无法被识别。 - 结果展示区:
显示每艘船舶的识别结果、可靠性、入坞可能性。如果成功,此处会出现一面旗帜。
了解此 UI 的工作原理将有助于您更顺利地执行攻击步骤。
接下来,让我们看一下代码,看看此屏幕上发生了什么。
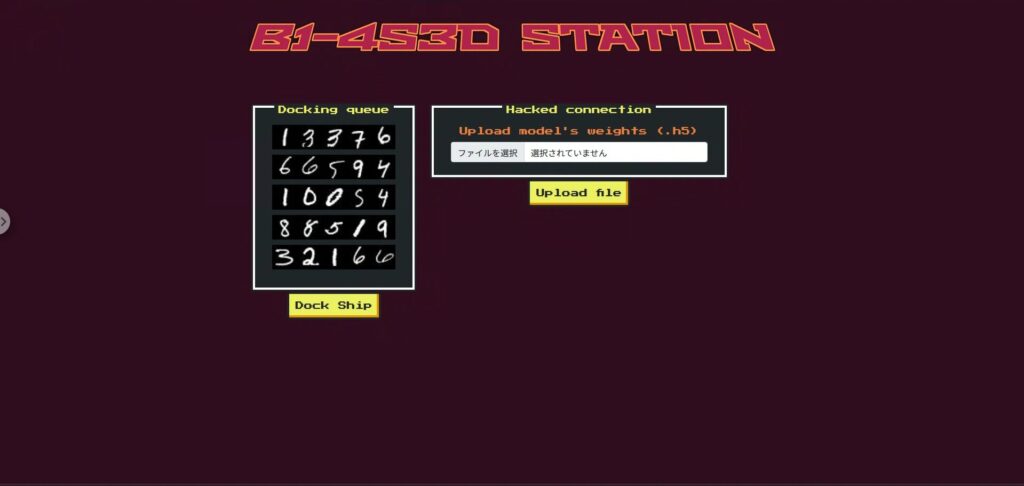
侦察阶段:检查被禁船只和模型交换机制
首先,尝试按下 Dock 按钮,您将看到一条消息,提示唯一被禁止的应用程序是“Phalcon”。
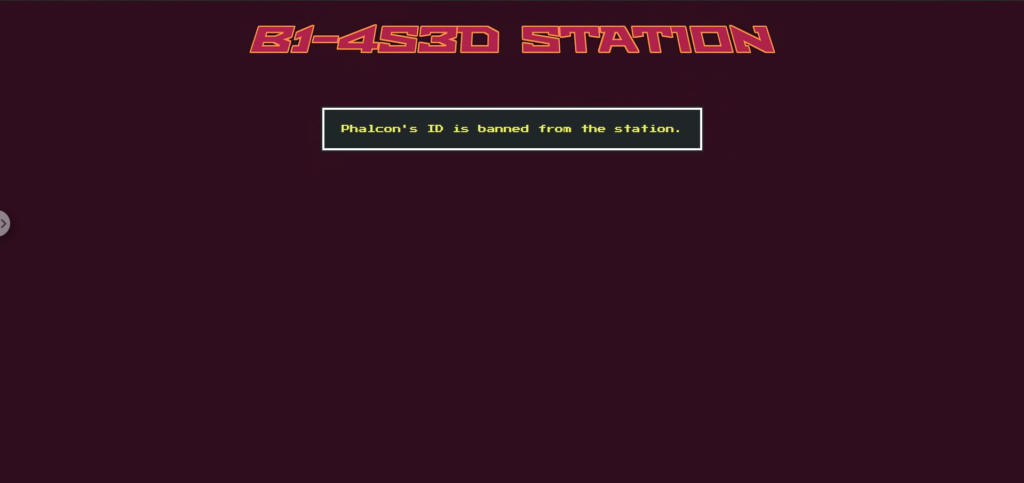
如果你查看源代码,你就会明白原因。在 /dock 端点,与其他飞船不同,Phalcon 会通过第二个门,并且将 validation_check=False 设置为 False ,这意味着它在解析图像时会跳过数字可靠性检查。
另外设置了self.bannedId = “32166”,如果最终的Phalcon ID变成这个值,就会引发异常,强制用户不通过。
@app.route('/dock', methods=['POST']) def dock(): try: for spaceship in b1_4s3d_station.spaceships: id, id_confidence = b1_4s3d_station.passFirstGate(spaceship.id_image) if spaceship.name == "Phalcon": b1_4s3d_station.passSecondGate(id, spaceship.id_image, id_confidence, validation_check=False) else: b1_4s3d_station.passSecondGate(id, spaceship.id_image, id_confidence) except DockingException as de: return render_template('dock.html', respond = spaceship.name+str(de)) except Exception as e: return render_template('dock.html', respond = '对接时出现意外错误。') return render_template('dock.html', respond = flag)侦察阶段:上传文件的作用
首页上的上传文件功能其实取代了第二门模型(second_gate)。
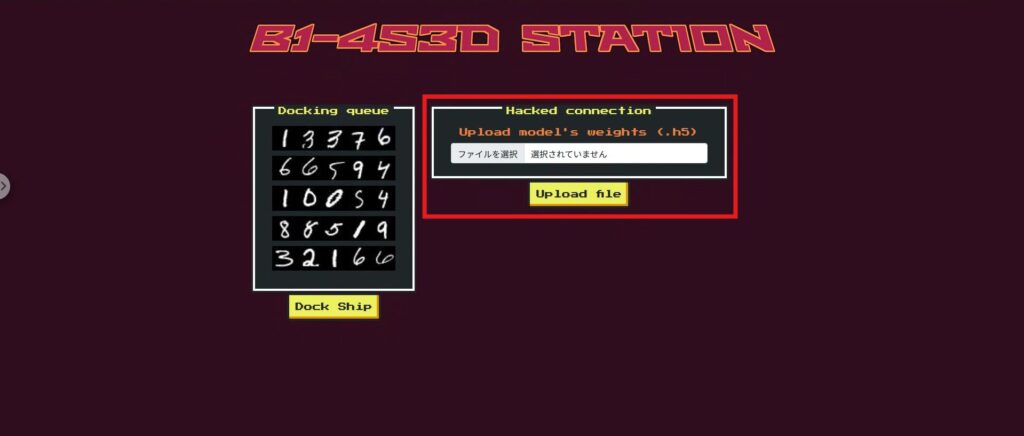
这意味着玩家可以通过上传自己修改过的 Keras .h5 模型来自由重写第二个门的决策逻辑。
@app.route('/', methods=['GET', 'POST']) def index(): ids = [] for spaceship in b1_4s3d_station.spaceships: ids.append(spaceship.idToBase64()) if request.method == 'POST': if 'file' not in request.files: return render_template('index.html', ids = ids, respond = "文件上传失败。") file = request.files['file'] if file.filename == '': return render_template('index.html', ids = ids, respond = "文件上传失败。") if file and allowed_file(file.filename): try: file.save(os.path.join(app.config['UPLOAD_FOLDER'], "uploaded.h5")) b1_4s3d_station.second_gate = tf.keras.models.load_model("./application/models/uploaded.h5") except: return render_template('index.html', ids = ids, response = "文件上传失败。") return render_template('index.html', ids = ids, respond = "文件上传成功。") else: return render_template('index.html', ids = ids)
侦察阶段:伪造哪些数字
值得注意的是,可靠性检查对除 Phalcon 之外的所有船只都有效,
因此,如果对第二个门的整个模型进行重大更改,其他船只将不再能够达到与门 1 相同的可靠性,从而导致整个门失败。

因此,我们将目标缩小到数字“2”,该数字仅在Phalcon的ID中出现。
通过大幅降低第二个门模型中“2”的可靠性,Phalcon的最终ID将变为与“32166”不同的数字字符串,从而使我们能够避开禁用ID检测。
此外,此更改不会影响其他舰船的ID。
侦察阶段:模型(.h5)
由于这是一场 CTF 比赛,服务器上原本使用的模型文件(.h5)已提前提供。
该文件是经过训练的神经网络模型,以 Keras 格式保存,可以使用上传功能将其替换为第二个门的模型。
攻击的目的是故意降低该模型对数字 2 的信心(预测分数)。
这将从 Phalcon 的 ID 中删除数字 2,使其避免被禁止使用 ID 32166。
接下来我们来看看如何实际加载和篡改这个.h5模型。
攻击阶段:仅禁用第二个门上的“2”即可避开禁止ID
我们将
仅将提供的训练模型(model.h5)的最终分类层(10 个类别)中对应于类别 2 的偏差元素-100 通过直接编辑 HDF5 而不使用 Keras,我们将创建一个替换模型(exploit.h5),同时保持文件结构和大小不变。
攻击脚本:
如果按原样运行以下命令,它将复制 model.h5 以创建exploit.h5,并将dense > dense >bias:0 中的index=2 重写为 -100。
import shutil, h5py, numpy as np shutil.copyfile("model.h5", "exploit.h5") # 按原样复制原始文件 with h5py.File("exploit.h5", "r+") as f: ds = f["model_weights/dense/dense/bias:0"] # dense > dense >bias:0 ds[2] = np.array(-100.0, dtype=ds.dtype) # 将 index=2 设置为 -100一旦脚本创建了exploit.h5,请在首页的上传文件部分中选择exploit.h5并上传。
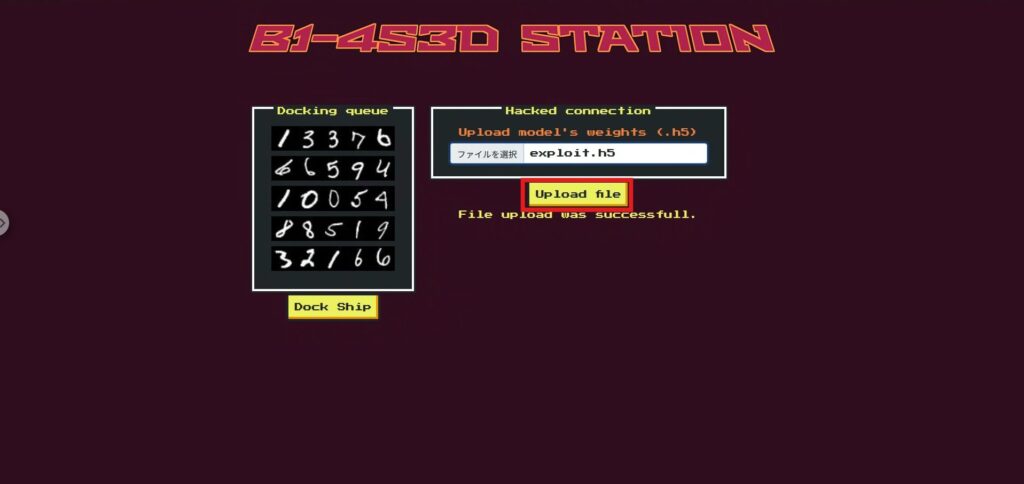
接下来运行 Dock(这里使用替换了 second_gate 的模型进行推理)。
现在,我们可以获取到 flag 了!

机制(为什么它起作用?)
简而言之,它“将2分的分数固定为几乎为零”。
- 则 softmax 之后“2”的概率将几乎为
- Phalcon 跳过第二道门的信任检查,只检查最终 ID 是否为 32166
- 由于未输出“2”,因此未配置32166 → 通过绕过禁止的ID检查而通过。
对策:防止在现实环境中发生模型篡改(类失效)
在这里,我们将范围缩小到仅包含那些在实际生产中有效的对策。我们删除了 CTF 特有的对策(例如跳过特定船只的验证、/playground 等),并将其通用化。
允许您随意上传模型的应用程序并不多,但如果您尝试上传模型,最好还是小心一点。
固定供应商(确保模型完整性)
生产中使用的模型将受到严格的管理,包括谁分发的、何时分发的、分发什么的,并且设计成不能被应用程序任意替换。
- 禁止运行时替换:生产环境中仅使用预构建的构件。不允许通过 UI/API 进行任意上传。
- 完整性验证:SHA-256 和签名(例如,Ed25519)在启动时和定期进行验证,任何故障都会导致立即故障关闭。
- 只读部署:模型存储在只读挂载/最小权限容器中运行。
负载卫生(不要直接信任不受信任的模型)
即使设计处理了用户提供的模型,除非经过隔离→转换→隔离,否则它们也无法投入生产。
- 格式和模式验证:机械地检查输入/输出形状、标签数量、允许的层类型以及参数上限。任何偏差均会被拒绝。
- 禁用危险的反序列化:禁用custom_objects并设置compile=False,避免阅读不必要的学习信息。
- 转换为安全格式:如果可能,统一为代码执行潜力较低的格式,例如 ONNX / SavedModel / safetensors。
- 隔离评估:导入操作在单独的进程/沙盒中执行,仅用于基准测试和健全性测试。生产数据和权限不受影响。
决策逻辑的鲁棒性(抵抗“破坏特定类别”的篡改)
不要仅仅依赖单一模型的输出。通过一致性检查和共识机制确保防篡改。
- 消除四舍五入比较:四舍五入到小数点后一位等操作会失败,且波动较小。两阶段检查:(a) 标签匹配 + (b) |p₁−p₂|≤ε。
- 验证与决策分离:验证模型仅用于验证(仅一致性检查),最终的决策由可信路径做出。
- 共识/冗余:重要决策由多个模型达成共识或结合使用规则做出,从而能够抵御单个模型的“类无效”。
- 健全性门:在部署之前自动检查每个类是否输出最小量(分布偏差、归零)。
运行监控和警报(及早发现异常)
确保可以通过操作检测并阻止篡改和损坏。
- 类别分布监控:当特定类别的发生率异常下降/变为零时发出警报。
- 哈希/签名日志:始终记录加载时的模型 ID、哈希、签名者和版本并通知更改。
- 保护性失败:当检测到异常时,自动回滚/切换到已知良好模型/暂时退回到规则判断。
摘要:可抵御模型篡改的 BYOM 设计
在本次挑战中,我们将一个自带 (BYOM) 模型直接连接到生产逻辑,并确认只需在输出层中某个位置篡改偏差,就能创建一个不会输出“2”的模型,从而绕过禁止的身份检查。虽然 AI 是智能的,但如果关于权重和输入/输出的假设被打破,其行为可能会发生巨大变化。这是最大的陷阱。
这种“直截了当”既是优势,也是攻击者的突破口:通过修改模型的内部结构,他们可以从外部改变应用程序预期的决策流程。
这就是为什么我们像对待代码一样对待模型,彻底实现隔离、验证和提升操作,并通过一致性而不是依赖舍入来保护判断。AI 并非万能,因此我们需要通过设计和操作来确保其稳健性。这是我们从这次经历中得到的最大教训。
从“欺骗AI”的角度来学习AI的工作原理,是一次非常实用且令人兴奋的体验。
如果你感兴趣,我们鼓励你“Hack the Box” 。
👉 有关如何注册 HackTheBox 以及各个计划之间的差异的详细信息,请单击此处。
![账号被盗?!我居然试了IDOR [HackTheBox Armaxis 评测]](https://hack-lab-256.com/wp-content/uploads/2025/12/hack-lab-256-samnail-300x169.png)
![[AI 安全] 使用即时注入攻击 AI 协商勒索软件 | HackTheBox TrynaSob 勒索软件 Writeup](https://hack-lab-256.com/wp-content/uploads/2025/08/hack-lab-256-samnail-31-300x169.jpg)
![[AI安全] 利用OpenAI函数调用进行AI代理劫持:实践与防御策略详解!HackTheBox忠诚度调查报告](https://hack-lab-256.com/wp-content/uploads/2025/08/hack-lab-256-samnail-30-300x169.jpg)
![[AI 安全] 利用即时注入欺骗法学硕士 | HackTheBox 外部事务报道](https://hack-lab-256.com/wp-content/uploads/2025/08/hack-lab-256-samnail-29-300x169.jpg)

![[Windows 10上的虚拟框]如何安装虚拟框的详细说明!](https://hack-lab-256.com/wp-content/uploads/2022/03/hack-lab-256-samnail-300x169.jpg)