

您是否曾经想真正将最近谈论的图像AI
在本文中,Next.js(App Router) , Tailwind CSS和OpenAI的Image Generation API(DALL·E 3)构建一个简单的图像生成应用
使用UI迅速工作的模板有点麻烦的人平台。
本文介绍的模板现已开始销售!
该聊天机器人UI模板可在多个平台上出售。
该结构非常适合那些想先尝试一些有效的东西的人,“我想立即使用它而不构建环境”,或者“我想检查整个代码”。
- 电容式非接触式系统独有的清脆打字感觉!
- REALFORCE首款无线兼容设备!有线连接也可用!
- 与 HHKB 不同,日语键盘布局没有任何怪癖,任何人都可以轻松使用!
- 配有拇指轮,水平滚动非常容易!
- 还拥有出色的降噪性能,安静舒适!
- 滚动可以在高速模式和棘轮模式之间切换!
关于所使用的技术
此图像生成应用是基于以下技术的:
- next.js(应用程序路由器配置)
-
基于React的框架使您可以构建统一的页面和API路由。我使用从
SRC/App应用程序路由器配置 - 尾风CSS
-
实用第一的CSS框架,可让您使用类有效地组织设计。快速创建一个响应迅速而简单的UI
- Openai API(图像生成)
-
使用
OpenAI的/V1/Images/Generations可以使用.env模型(例如DALL-E-3),图像大小,图像质量等。 - API路线 +提取
-
Next.js中的
/api /image在服务器端中继。
客户端具有简单的配置,可以简单地使用fetch(“/api/image”)
创建OpenAI API键
这次,我们将使用OpenAI API,因此我们需要创建一个OpenAI API密钥。
您将被重定向到OpenAI API仪表板中的API键。选择“创建新的秘密密钥”。
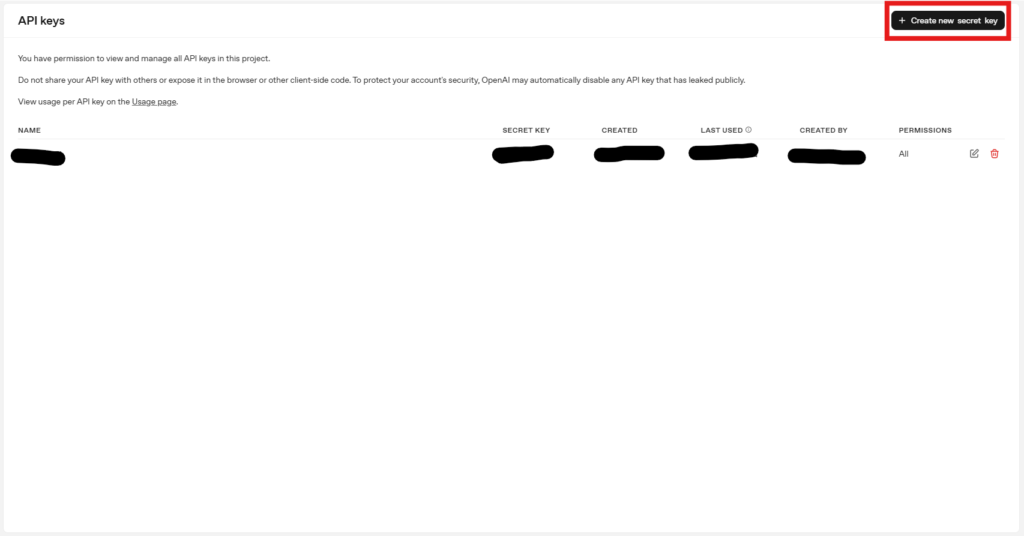
您可以将项目选出任何您喜欢的项目,然后选择适合要使用的模型的权限,或选择全部生成它。
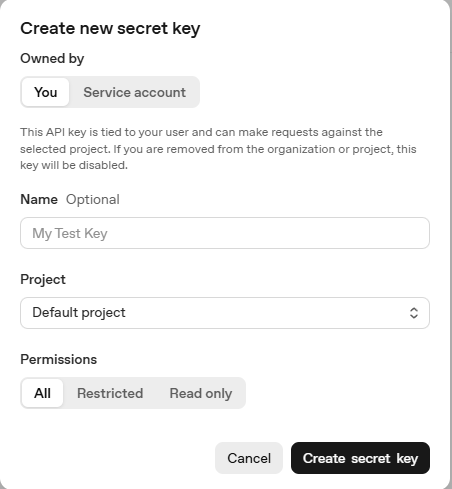
创建完成后,将创建一个以“ SK-”开头的字符串,因此我们将在此之后使用它。
请注意不要放弃此钥匙。
环境建设
首先,为下一步准备开发环境。
创建一个项目
我将创建一个项目。
基本上,我认为将所有内容都放在默认设备上是可以的,但是只要您可以根据需要更改它,就可以。
(该项目使用尾风CSS,因此最好将其设置为“是”。默认值为是。)
$ npx create-next-app@最新映像 - 生成器启动 - typescript✔您想使用eslint吗? …否 /是✔您想使用尾风CSS吗? …否 /是✔您想在`src /`目录中的代码吗? …否 /是✔您想使用应用程序路由器吗? (推荐)…否 /是✔您想将Turbopack用于“ Next Dev”? …否 /是✔您想自定义导入别名(`@ /*'默认情况下)? …否 /是在 /图像生成器启动器中创建一个新的Next.js应用程序。使用NPM。使用模板初始化项目:App -tw安装依赖项: - 反应 - react -dom-下一个安装DevDepties: - typescript- @ @type/node- @types/types/react- types/react- @ @type/react- type/ @type/react-doess/react-dom- @tailwindcss/postcss/postcss/postcss -paintcss -eSlint -eslint -eslint -eSlint -slint -eSlint-config-neftige 37 packity 37 packity 33333336在16S中,137个软件包正在寻找资金运行“ NPM基金”,以获取0个漏洞的详细信息,初始化了GIT存储库。成功!创建的图像生成器启动器 /图像生成器启动器如果出现“成功!创建的图像生成器启动器”,则会出现“图像生成器启动器”,则项目创建已完成。
创建项目后,移动目录。
CD图像生成器启动器设置OpenAI API密钥
在根中创建一个.env
OpenAI_API_KEY = SK -... OpenAi_Model = dall-e-3 Openai_image_size = 1024x1024 OpenAi_image_Quality =标准简短描述:
- OpenAI_API_KEY :访问OpenAi Image Generation API的私钥(从OpenAI管理屏幕获得)
- OpenAi_Model :要使用的图像生成模型。当前,
DALL-E-3(也支持未来更新) - OpenAI_IMAGE_SIZE :要生成的图像的大小(例如
1024x1024)。可以根据需要更改 - OpenAI_IMAGE_QUALITY :图像质量。您可以选择
标准或高清高清是高质量的,但可能需要很长时间)
启动开发服务器
运行以下命令将启动模板:
NPM运行开发实施UI(图像生成屏幕)
图像生成用户界面被组织到src/app/page.tsx源代码的总量如下:
“使用客户端”;从“ react”导入{usestate};从“下一/图像”导入图像;导出默认函数home(){//用户输入(图像提示符)的状态//用户const [提示,setPrompt] = usestate(“”)输入的图像生成提示符; //存储生成的图像URL //生成的图像const [imageUrl,setImageUrl] = usestate(“”); //加载指示器状态//加载标志const [加载,setloading] = usestate(false); //错误消息状态//用于存储错误消息const [错误,setError] = usestate(“”); //处理映像生成请求//处理图像生成请求const generateImage = async()=> {if(!strive.trim())return; //请求之前重置状态//在请求setloading(true)之前初始化状态; seterror(“”); setImageUrl(“”);尝试{//将请求发送到内部API //将请求发送到内部API(/api/image)const res =等待fetch(“/api/image”,{方法:“ post”,标题:{“ content-type”:“ application/json”},“ application/json”},body:json.stringify(strips}),},},},},}); const data =等待res.json(); if(res.ok && data.imageurl){setImageUrl(data.imageurl); } else {setError(data.error ||“无法生成图像。”); }} catch(e){console.error(“错误:”,e); setError(“发生意外错误。”); }最后{setloading(false); }};返回 (<main className="min-h-screen bg-gray-900 text-gray-100 flex items-center justify-center px-4 py-8"><div className="w-full max-w-xl bg-gray-800 rounded-xl shadow-lg p-6 space-y-6"> {/* 标题 */}<h1 className="text-2xl font-bold text-center text-white"> AI图像发生器</h1>{/ *提示输入/提示输入字段 */}<div className="space-y-2"><label htmlFor="prompt" className="block text-sm font-medium text-gray-300" >输入您的图像提示</label><textarea id="prompt" rows={3} value={prompt} onChange={(e) =>setPrompt(e.target.value)} className="w-full p-3 rounded-lg bg-gray-700 border border-gray-600 text-white focus:outline-none focus:ring-2 focus:ring-green-400 resize-none" placeholder="eg A futuristic cityscape at sunset, digital art" /> </div> {/* Generate Button / Generate button */} <button onClick = {generateImage} disabled = {loading} className =“ W-Full Py-3圆形LG BG-Green-500 Hover:BG-Green-600 Text-Black Font-Semibold disabled disabled:opacity-50 transition-50 transition-transition”> {加载? “生成...”:“生成映像”} </button> {/ *错误消息/错误显示 */} {error &&(<div className =“ text-red-red-400 text-red-red-sm text-sm text-center”> {error} </div>)}} {/ * <image src = {imageUrl} alt =“生成结果”填充未优化的className =“圆形lg对象 - 符合符号边框灰色-700”/> </div>)} </div> </div> </main>); }
消息状态管理
const [提示,set prompt] = usestate(“”); const [imageurl,setImageUrl] = usestate(“”); const [加载,setloading] = usestate(false); const [error,setError] = usestate(“”);简短描述:
提示:保留用户输入的图像生成描述(提示)ImageUrl:保留生成图像的URL加载:表示等待API响应的状态错误:在发生错误时保留要显示的消息
图像生成传输处理和API调用
const generateImage = async()=> {if(!strip.trim())返回; setloading(true); seterror(“”); setImageUrl(“”);尝试{const res =等待fetch(“/api/image”,{方法:“ post”,标题:{“ content-type”:“ application/json”},body:json.stringify(atrive {strive}),},},}); const data =等待res.json(); if(res.ok && data.imageurl){setImageUrl(data.imageurl); } else {setError(data.error ||“无法生成图像。”); }} catch(e){console.error(“错误:”,e); setError(“发生意外错误。”); }最后{setloading(false); }};简短描述:
- 将输入的提示发送
/api /image - 从OpenAI API返回图像时,将URL设置为屏幕上。
- 如果发生错误,将显示一条消息
输入形式和按钮(尾风CSS)
<textarea id="prompt" rows={3} value={prompt} onChange={(e) =>setPrompt(e.target.value)} className =“ w-full p-3圆形lg bg-gray-700边界边界边界灰色-600文本 - 白色焦点:列出焦点:ring-2焦点:ring-green-400 resize nosize nosize osize notize osize of-none“ losthorder”占位符= className =“ W-Full Py-3圆形LG BG-Green-500 Hover:BG-Green-600 Text-Black Font-Semibold disabled:opacity-50 Transition”> {加载? “生成...”:“生成图像”} </button>简短描述:
- 在文本区域中输入图像描述
- 单击按钮开始图像生成(
加载时禁用按钮 - 尾风CSS使其简单易用
图像显示,错误,加载显示
{错误 && (<div className="text-red-400 text-sm text-center"> {错误}</div> )} {imageUrl &&(( <div className="mt-4 relative w-full h-[512px]"><Image src={imageUrl} alt="Generated result" layout="fill" className="rounded-lg object-contain border border-gray-700" /></div> )简短描述:
- 如果有
错误 - 如果生成图像,它将在屏幕上响应地显示(使用
Next/image
服务器端实现(OpenAI API集成)
图像生成的过程是客户端将请求发送到/API /图像然后将继电器和响应返回到服务器上的OpenAI聊天API。
服务器端源代码的总量如下:
// src/app/api/image/route.ts import {nextrequest,nextresponse}从“ next/server”; //使用OpenAI API //使用OpenAI API Post Handler Export async函数帖子(req:nextrequest){//从请求正域中解析提示符//从请求const {提示} =等待req.json(); //验证输入//检查是否指定了提示,如果(!提示){return nextresponse.json({error:“需要提示:“需要提示”},{状态:400}); }尝试{//从环境变量(带后式值)加载配置//来自环境变量的加载设置(如果不是,默认值)const model = process.env.openai_model || “ dall-e-3”; const size = process.env.openai_image_size || “ 1024x1024”; const质量= process.env.openai_image_quality || “标准”; //将请求发送到OpenAI的图像生成端点//将请求发送到OpenAi的图像生成端点const ands witch = ategat Fetch(“ https://api.openai.com/v1/images/generations'身体:JSON.STRINGIFY({模型,// EG,“ dall-e-3”提示符,//用户提示图像生成大小的提示,// eg,“ 1024x1024”质量,// // //“标准”或“ hd” n:1,// // to Generation}的图像}) const data =等待响应.json(); //如果(data.error){Console.Error返回API错误,请处理API错误响应//该怎么办(“ OpenAI API错误:”,data.error);返回nextresponse.json({error:“图像生成失败”},{状态:500}); } //提取生成的图像URL //获取生成的Image const imageUrl = data.data?. [0]?url; //将映像URL返回客户端//返回映像URL返回客户端返回nextresponse.json({imageurl}); } catch(error){//处理意外服务器错误//处理意外的服务器错误console.error(“服务器错误:”,错误);返回nextresponse.json({error:“内部服务器错误”},{状态:500}); }}}
路由的基本配置
从“ next/server”导入{nextrequest,nextresponse};导出异步函数帖子(req:nextrequest){const {stress} =等待req.json();简短描述:
- 这是仅限于
发布 - 您会收到从客户端发送的
提示
OpenAI API的请求
const响应=等待fetch(“ https://api.openai.com/v1/images/generations”,{方法:“ post”,标题:{授权:'bearer $ {process.env.env.openai_api_key} process.env.openai_model ||。 const data =等待响应.json();简短描述:
- 动态加载来自环境变量的
API键,模型名称,图像大小和图像质量 - OpenAI Image Generation API(
/V1/Images/Generations),然后发送图像生成请求。 n:1是“只生成一张纸”的规范。
响应处理和错误处理
if(data.error){console.error(data.error);返回nextresponse.json({error:“图像生成失败”},{状态:500}); } const imageUrl = data.data?. [0]?返回nextresponse.json({imageurl}); }简短描述:
- 如果OpenAI API失败,则该错误将输出到控制台,并以500误差返回。
- 如果成功返回图像URL,它将返回给客户端(
imageurl)。
[奖励]要注意的事情
- 请
使用.env,以免您发布它们如果问题发生,OpenAI管理屏幕上重新发行 - 型号名称,图像大小和图像质量设计
.env动态切换请根据目的和成本进行调整(例如HD质量更高,成本高于标准) - 图像存储期和可用性时间可能会受到限制,因此,如果需要,请考虑设计以在获取后立即执行存储处理。
操作检查
让我们快速检查一下其操作!
当您在浏览器中打开“ Localhost:3000”时,将会显示以下屏幕。
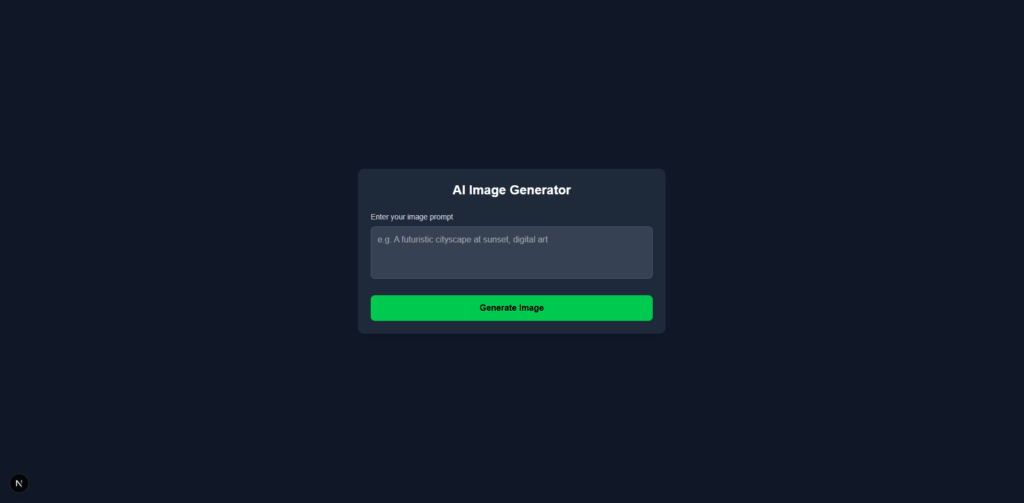
尝试进入“一只可爱的猫”。
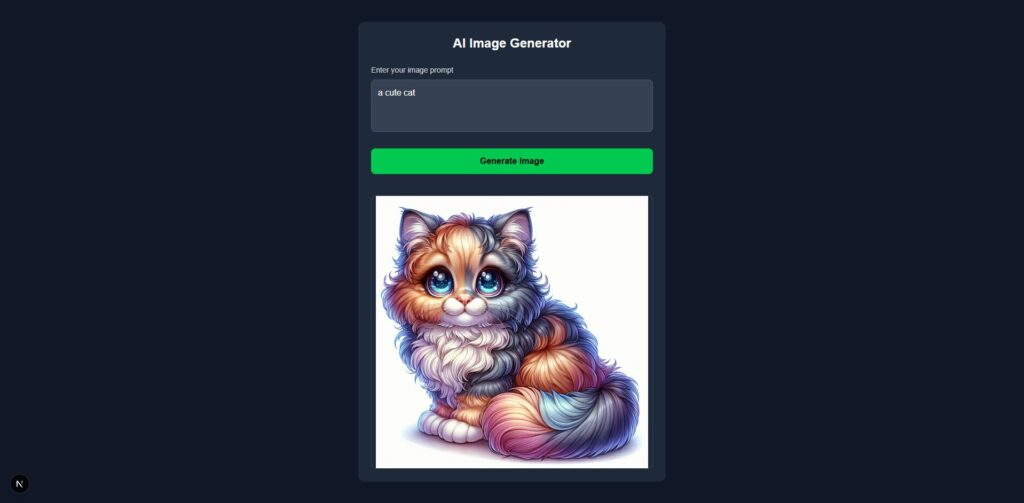
等待了一段时间后,生成并展示了一个可爱的猫图像!
它还显示日语中没有任何问题!
有关模板销售的信息
本文中介绍的聊天机器人UI还作为模板出售,可用于商业目的
为什么要卖模板?
我们已经为那些经历以下需求的人做好了准备:
- “即使您遵循这些步骤,环境也无法解决……”
- “我只想从一个移动的样本开始。”
- “我查看了我的博客,发现它很有用,因此我想购买它以支持和捐赠的目的。”
即使是那些不习惯开发游戏的人也能够启动并以最少的努力快速尝试
模板使用的示例(自定义想法)
该模板非常适合个人发展和学习目的。
例如,我们建议修改和扩展以下内容:
- 添加了预处理器以翻译输入提示英语
- 扩展以允许下载并保存并在SNS上共享生成的图像
- 在本地添加历史管理(最新提示 +图像)功能
- 自定义主题颜色和设计以制定自己的规格
- 添加处理以自动将图像保存到服务器端的S3等。
对于编程初学者来说,这也是一个很好的做法。
模板中包含的内容
包含
我们此处介绍的项目的所有源代码因此,您无需从头开始创建或配置自己的项目,就可以立即开始。
- UI使用Next.js(App Router)实现
- API集成的服务器端实现
- 用评论清洁代码结构
- 使用尾风CSS简单易于改进设计
- Docker启动配置文件(
Dockerfile,Docker-Compose.yml)
本文介绍的模板现已开始销售!
该聊天机器人UI模板可在多个平台上出售。
该结构非常适合那些想先尝试一些有效的东西的人,“我想立即使用它而不构建环境”,或者“我想检查整个代码”。
概括
这次,我们介绍了如何使用OpenAI API X Next.js图像生成应用。
本文的要点如下:
- OpenAI的图像API允许您使用一点点代码创建图像生成功能
- next.js应用程序路由器 +尾风CSS使扩展和自定义UI变得容易
- 使用模板,跳过环境构建和设置,并立即检查操作。
该模板非常适合
原型制作和个人开发入门套件也建议那些想快速将自己的想法变为现实或学习和验证OpenAI API的人。
![如何构建一个自动在Chatgpt + Next.js [OpenAI API + NEXT.JS + Tailwind CSS]中自动生成LP的Web应用程序]](https://hack-lab-256.com/wp-content/uploads/2025/07/hack-lab-256-samnail-27-300x169.jpg)
![我尝试使用OpenAI API [Next.js + Tailwind CSS]创建聊天机器人](https://hack-lab-256.com/wp-content/uploads/2025/07/hack-lab-256-samnail-25-300x169.jpg)

![[对于初学者]介绍三个光纤X DREI X打字稿!从图像创建像素艺术和动态动画](https://hack-lab-256.com/wp-content/uploads/2025/02/hack-lab-256-samnail-16-300x169.jpg)
![[完整说明]用React三个光纤×打字稿学习! 3D对象转换(位置,旋转,比例)的实用指南](https://hack-lab-256.com/wp-content/uploads/2025/02/hack-lab-256-samnail-15-300x169.png)
![[超级简单]介绍三个光纤X DREI X打字稿!用标准对象制造的oke oke样式3D背景!](https://hack-lab-256.com/wp-content/uploads/2025/02/hack-lab-256-samnail-14-300x169.jpg)

