

AIは「学習して判断する」だけでなく、その判断の元となるモデル自体が攻撃対象になる時代になりました。
特に機械学習モデルの重みやバイアスは、その出力結果を決定づける中枢であり、ここを改ざんされると予測結果を意図的に歪められます。
こうしたモデル改ざん攻撃(Model Manipulation / Targeted Misclassification)は、特定のクラスを常に誤認識させたり、検知システムをすり抜けたりするために悪用される危険性があります。
例えば監視カメラやOCR認証システムで「特定の人物やナンバーだけを見逃す」ことも可能です。
今回は、HackTheBoxのCTFチャレンジ Fuel Crisis を通じて、モデルの最終層バイアスを改ざんし、特定クラス(数字「2」)を完全に無効化する方法を実践します。
さらに、その過程で学べるAIセキュリティの基礎と、防御のためのポイントについても解説します。
- 静電容量無接点方式ならではのスコスコとした打鍵感!
- REALFORCE初のワイヤレス対応!有線接続も可能!
- HHKBと違って、日本語配列に癖がなく誰でも使いやすい!
- サムホイールが搭載、横スクロールがかなり楽に!
- 静音性能も高く、静かで快適!
- スクロールは、高速モードとラチェットモードを使い分け可能!
HackTheBoxについて
今回は、実際にHackTheBox(HTB)というプラットフォームを使って、脆弱性の検証を行っています。
HackTheBoxは、Webアプリケーションやサーバ、ネットワークなど、さまざまなセキュリティ分野の演習ができる実践型CTFプラットフォームです。
実際に攻撃対象となるマシンやアプリケーションにアクセスして、手を動かしながら学べるのが最大の特徴です。
今回取り上げる「Fuel Crisis」は、HackTheBoxで過去に提供されていたChallengeカテゴリの1つで、現在はVIPプラン以上に加入しているユーザーのみがアクセス可能なマシンです(※無料プランではアクティブなチャレンジのみが対象になります)。
他にも、Web、Reversing、Pwn、Forensicsなど多様なカテゴリのマシンやチャレンジが揃っており、自分のレベルに合わせて取り組めるのが魅力です。
HackTheBoxで本格的にスキルを磨きたい方は、ぜひVIPプランに登録して、過去のマシンやChallengeを存分に活用してみてください。
👉 HackTheBoxの詳しい登録方法や、プランの違いはこちらをご確認ください。

チャレンジ概要:Fuel Crisis
この課題は、宇宙船「Phalcon」が燃料不足の中、入港禁止となっている宇宙ステーション B1-4S3D にどうにかしてドッキングする、という設定です。
ステーションのゲートには2台のOCRカメラがあり、1台目が読み取った船のIDと信頼度を、2台目で再判定して照合します。2つの結果が大きく異なると入港拒否となります。
幸い、仲間のハッカーが2台目カメラのモデルファイルアップロード権限を奪取し、さらに自分の船が通過する瞬間は検証プロセスを無効化できる状態になっています。
プレイヤーの任務は、この状況を利用してモデルの内部パラメータを改ざんし、自分の船のIDに含まれる数字「2」だけを絶対に認識させないようにすることです。
ポイント
- 攻撃対象:宇宙ステーションの2台目OCRカメラで動作する機械学習モデル(Keras / h5形式)
- 目的:数字「2」を常に誤認識させ、自分の船のIDを正しい形で検知させない
- 手法:モデル最終Dense層の「2」クラス用バイアス値を大きな負数(例:-100)に設定
- 成功条件:他の船(4隻)は正しく認識され、自分の船の数字「2」だけが認識されない状態でドッキング成功
Keras と h5形式とは?
Fuel Crisisでは、h5ファイル内の最終Dense層のバイアス値を直接書き換えることで、特定のクラス(数字「2」)の出力を強制的に低くし、絶対に認識されないようにしています。
Keras
Kerasは、Pythonで使える高水準のディープラーニングフレームワークです。
TensorFlowやTheanoなどのバックエンドを簡単に操作できるようにしたライブラリで、直感的なAPIでモデルを構築・学習・保存できます。
今回のFuel Crisisでは、OCR(文字認識)モデルがKerasで作られており、学習済みの重みが配布されています。
h5形式
.h5は、HDF5(Hierarchical Data Format version 5)というデータ保存フォーマットの拡張子です。
Kerasでは学習済みモデルやその重みをh5形式で保存できます。
この形式は階層構造を持ち、Dense層やConvolution層など各レイヤーの重み(weights)やバイアス(biases)をそのまま格納できます。
テキストエディタでは読みにくいですが、h5pyやHDFViewといったツールで中身を開き、直接編集することが可能です。
モデル改ざんによる特定クラス無効化とは?
モデル改ざんによる特定クラス無効化 は、学習済みAIモデルの内部パラメータを書き換えることで、特定のクラスが絶対に予測されないようにする攻撃手法です。
例えばOCRや顔認証などで、特定の数字や人物を常に誤認識させ、検知を回避できます。
この手法は推論段階(inference)での挙動改変にあたり、入力データを変える攻撃(敵対的サンプル)とは異なり、モデル自体の中枢を直接操作します。
攻撃の仕組み
この攻撃は、機械学習モデルが最終的に出すクラスごとのスコアを、内部パラメータで意図的に操作することで成立します。
具体的には、最終層(Dense層など)のバイアス値を極端な負数にすることで、そのクラスのスコアが常に低くなり、予測対象から外れます。
他のパラメータは変更しないため、全体の挙動や信頼度はほぼ変わりません。
- バイアス値を大きく負にする → 該当クラスは常に低スコア
- 他のクラスの精度はほぼ維持されるため、改ざんが目立たない
- Fuel Crisisでは数字「2」が対象クラス
攻撃の流れ
この攻撃は次のようなステップで実行されます。
- 学習済みモデルファイル(.h5形式)を取得
- h5py や HDFView で中身を開き、最終Dense層の「クラス2」に対応するバイアス値を特定
- そのバイアス値を極端な負数(例:-100)に書き換え
- 改ざんしたモデルをシステムに再アップロード
- 推論時に「2」が含まれるIDは必ず別の数字として誤認識され、検知を回避
成立する条件
この攻撃が成立するには、いくつかの前提条件があります。
条件が揃っていない環境では、改ざんを行っても意図した効果は得られません。
- 攻撃者がモデルファイルを直接取得・編集できる
- モデルアップロード時に改ざん検証(署名やハッシュチェック)が行われない
- 特定クラスを無効化しても他の挙動に目立った影響が出ない
実際にハッキングしてみた!
攻撃に入る前に、まずはFuel CrisisのWebアプリ画面を簡単に説明しておきます。
このアプリは、宇宙ステーションのドッキングゲートを模したUIで、5隻の宇宙船が順番に通過します。各船にはOCRで読み取られる船ID(数字列)が割り当てられています。
画面上には大きく分けて以下の要素があります。
- 船ID表示領域
5隻分のID画像が並びます。自分の船は最後に通過し、IDには数字「2」が含まれています。 - モデルファイルアップロードフォーム
.h5形式のモデルファイルを選択してアップロードできます。ここで改ざんモデルを投入します。 - Dockボタン
5隻分のIDをOCRモデルで判定し、ドッキング可否を判定します。改ざんが成功していれば、自分の船だけ認識を回避できます。 - 結果表示エリア
各船の認識結果や信頼度、ドッキング可否が表示されます。成功時はフラグ(Flag)がここに出ます。
このUIの仕組みを理解しておくと、後の攻撃手順がスムーズに追えます。
次は、この画面で何が起きているのかをコードとともに見ていきましょう。
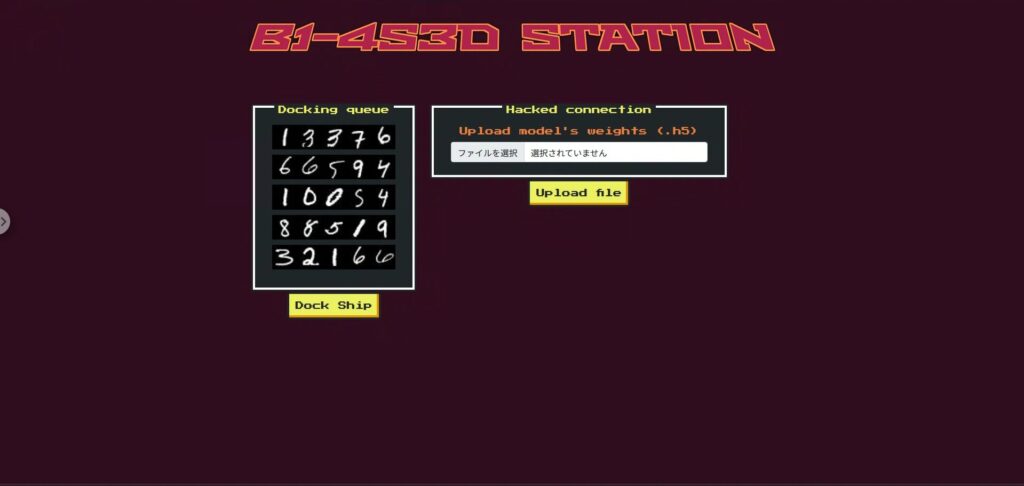
偵察フェーズ:禁止されている船とモデル差し替えの仕組みを確認
まずは試しに Dock ボタンを押してみると、唯一「Phalcon」だけが禁止されているというメッセージが表示されます。
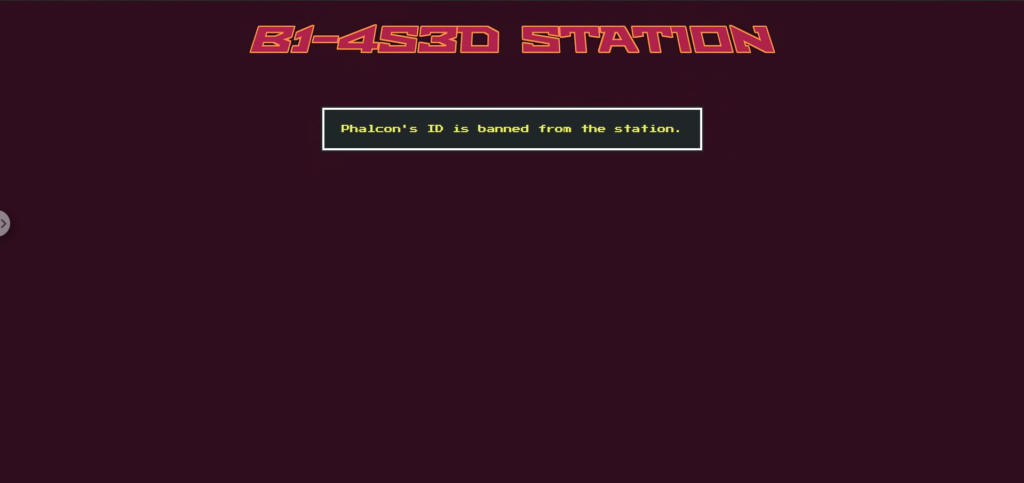
ソースコードを確認すると、その理由がわかります。/dock エンドポイントでは、他の宇宙船と違い Phalcon だけ validation_check=False で第2ゲートを通過するようになっています。これは、画像解析の際に数字の信頼度チェックをスキップする設定です。
さらに、self.bannedId = “32166” が設定されており、Phalcon の最終的なIDがこの値になると例外が発生し、強制的に通過できなくなっています。
@app.route('/dock', methods=['POST'])
def dock():
try:
for spaceship in b1_4s3d_station.spaceships:
id, id_confidence = b1_4s3d_station.passFirstGate(spaceship.id_image)
if spaceship.name == "Phalcon":
b1_4s3d_station.passSecondGate(id, spaceship.id_image, id_confidence, validation_check=False)
else:
b1_4s3d_station.passSecondGate(id, spaceship.id_image, id_confidence)
except DockingException as de:
return render_template('dock.html', response = spaceship.name+str(de))
except Exception as e:
return render_template('dock.html', response = 'Unexpected error while docking.')
return render_template('dock.html', response = flag)偵察フェーズ:Upload file の役割
トップページの Upload file 機能は、実は第2ゲートのモデル (second_gate) を差し替える処理になっています。
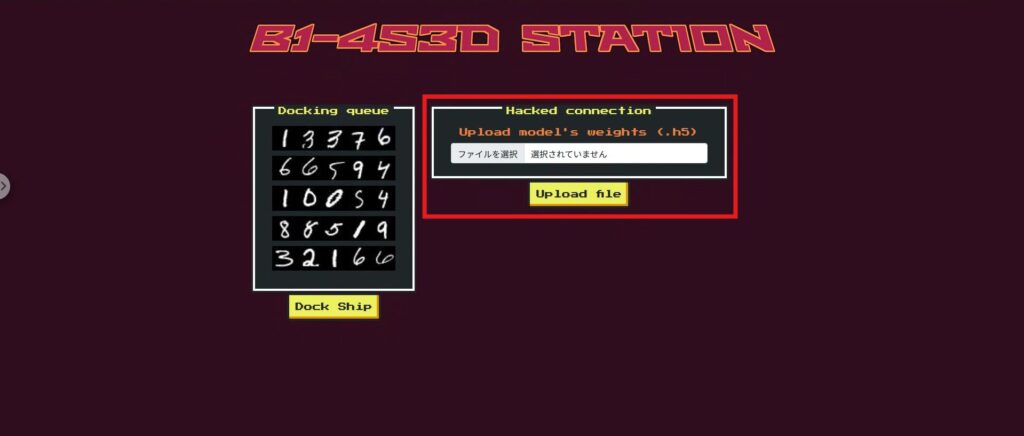
つまり、プレイヤーは独自に改造した Keras の .h5 モデルをアップロードすることで、第2ゲートの判定ロジックを自由に書き換えることができます。
@app.route('/', methods=['GET', 'POST'])
def index():
ids = []
for spaceship in b1_4s3d_station.spaceships:
ids.append(spaceship.idToBase64())
if request.method == 'POST':
if 'file' not in request.files:
return render_template('index.html', ids = ids, response = "File upload failed.")
file = request.files['file']
if file.filename == '':
return render_template('index.html', ids = ids, response = "File upload failed.")
if file and allowed_file(file.filename):
try:
file.save(os.path.join(app.config['UPLOAD_FOLDER'], "uploaded.h5"))
b1_4s3d_station.second_gate = tf.keras.models.load_model("./application/models/uploaded.h5")
except:
return render_template('index.html', ids = ids, response = "File upload failed.")
return render_template('index.html', ids = ids, response = "File upload was successfull.")
else:
return render_template('index.html', ids = ids)
偵察フェーズ:どの数字を改ざんするか
ここで注意が必要なのは、Phalcon 以外の船は信頼度チェックが有効だという点です。
もし第2ゲートのモデル全体を大きく改変すると、他の船がゲート1と同じ信頼度を出せなくなり、全体が失敗してしまいます。

そこで、狙いを Phalcon の ID にしか含まれない数字「2」 に絞ります。
第2ゲートのモデルで「2」の信頼度を大きく下げれば、Phalcon の最終IDは「32166」から別の数字列になり、禁止ID判定を回避できます。
さらに、この変更は他の船のIDには影響しません。
偵察フェーズ:モデル(.h5)
今回は CTF ということもあり、元々サーバーで使用されているモデルファイル(.h5)は事前に提供されています。
このファイルは Keras 形式で保存されたニューラルネットワークの学習済みモデルで、アップロード機能を使えば第2ゲートのモデルと差し替えることができます。
攻撃の狙いは、このモデルの「数字2」に対応する信頼度(予測スコア)だけを意図的に低くすることです。
これによって、Phalcon の ID から「2」が消え、禁止ID 32166 を回避できるようになります。
次は、この .h5 モデルを実際に読み込み、改ざんする方法を見ていきます。
攻撃フェーズ:第2ゲートの“2”だけを無効化して禁止IDを回避
やることはシンプルです。提供された学習済みモデル(model.h5)の最終分類層(10クラス)のバイアスのうち、クラス2に対応する要素だけを-100に上書きします。
Kerasは使わず HDF5を直に編集することで、ファイル構造とサイズを保ったまま差し替え用モデル(exploit.h5)を作ります。
攻撃用スクリプト:
以下をそのまま実行すると、model.h5 をコピーして exploit.h5 を作成し、dense > dense > bias:0 の index=2 を -100 に書き換えます。
import shutil, h5py, numpy as np
shutil.copyfile("model.h5", "exploit.h5") # 元をそのままコピー
with h5py.File("exploit.h5", "r+") as f:
ds = f["model_weights/dense/dense/bias:0"] # dense > dense > bias:0
ds[2] = np.array(-100.0, dtype=ds.dtype) # index=2 を -100 にスクリプトで exploit.h5 ができたら、トップページの Upload file で exploit.h5 を選択してアップロードしましょう。
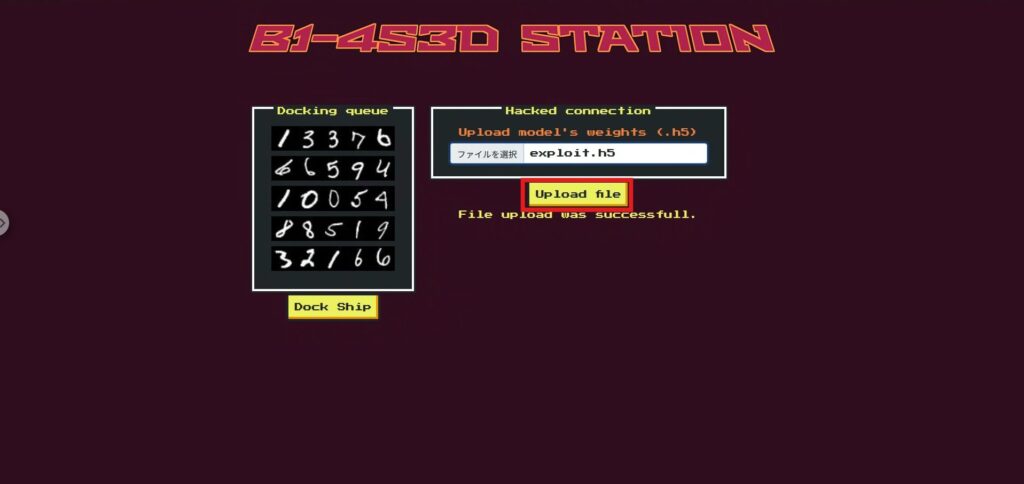
続けて Dock を実行(ここで second_gate が差し替わったモデルで推論)
これで、フラグの取得ができました!

仕組み(なぜ通る?)
短く言うと、“2のスコアをほぼゼロに固定する”からです。
- 出力層でクラス2のバイアスを -100にすると、softmax後の「2」の確率はほぼ0になります
- Phalconは第2ゲートで信頼度照合がスキップされ、最終IDが 32166 かどうかだけを見られます
- 「2」を出さないため 32166 が構成されない → 禁止IDチェックを回避して通過します
対策:モデル改ざん(クラス無効化)を現実環境で起こさせないために
ここでは 実プロダクションでも有効な対策だけ に絞って整理しました。CTF固有(特定艦だけ検証スキップ、/playground 等)は削除し、一般化しています。
モデルを任意アップロードできるようなアプリはあまり見かけませんが、モデルをアップロードさせようとしていた方は注意をしておくと良いかと思います。
供給元の固定化(モデルの完全性を担保)
本番で使うモデルは “誰が・いつ・何を” 配布したかを厳密に管理し、アプリ側で勝手に差し替えられない設計にします。
- ランタイム差し替え禁止:本番はビルド済みアーティファクトのみ。UI/APIによる任意アップロードは不可。
- 完全性検証:起動時と定期で SHA-256 や 署名(例:Ed25519) を検証し、失敗は即フェイルクローズ。
- 読み取り専用配置:モデル格納は read-only マウント/最小権限コンテナで実行。
読み込みの衛生(Untrustedなモデルを直接信じない)
万一ユーザー提供モデルを扱う設計でも、検疫→変換→隔離を通さない限り本番に入れない。
- 形式・スキーマ検証:入出力形状・ラベル数・許可レイヤ種別・パラメータ上限を機械的に検査。逸脱は拒否。
- 危険なデシリアライズ禁止:custom_objects を無効化、compile=False で余計な学習情報を読まない。
- 安全形式への変換:可能なら ONNX / SavedModel / safetensors などコード実行性の低い形式に統一。
- 隔離評価:取り込みは別プロセス/サンドボックスでベンチ・健全性テストのみ。本番データや権限に触れさせない。
判定ロジックの堅牢化(“特定クラスを潰す”改ざんに強く)
単一モデルの出力に丸投げしない。一貫性検査と合議で改ざん耐性を持たせる。
- 丸め比較の廃止:小数1桁丸め等は微小変動で破綻。(a) ラベル一致+(b) |p₁−p₂|≤ε の二段チェックに。
- 照合と決定の分離:検証モデルは照合専用(一貫性チェックのみ)。最終決定は信頼済み経路で行う。
- 合議/冗長化:重要判定は複数モデルの合議やルール併用で、単一モデルの“クラス無効化”に耐性を。
- 健全性ゲート:デプロイ前に各クラスが最低限出力されること(分布の偏り、ゼロ化)を自動チェック。
運用監視・アラート(異常を早期検知)
改ざんや劣化を運用で検知・遮断できるようにしておく。
- クラス分布監視:特定クラスの出現率が異常に低下/ゼロになったらアラート。
- ハッシュ/署名ログ:ロード時にモデルID・ハッシュ・署名者・バージョンを必ず記録し、変更を通知。
- 保護的フェイル:異常検知時は自動ロールバック/既知良好モデルへの切り替え/一時的にルール判定へ退避。
まとめ:モデル改ざんに負けない BYOM 設計
今回のチャレンジでは、持ち込みモデル(BYOM)をそのまま本番ロジックに接続した結果、出力層のバイアスを一箇所改ざんするだけで「2」を出さないモデルを作り、禁止IDチェックを回避できることを確認しました。AIは賢い一方で、重みや入出力の前提が崩れると挙動を大きく変える。ここが最大の落とし穴です。
この“素直さ”は長所であると同時に、攻撃者にとっての入口にもなります。モデルの内部を少し弄るだけで、アプリの期待する判定フローを外側からねじ曲げられるのです。
だからこそ、モデルもコード同様に扱い、検疫・検証・昇格の運用を徹底し、判定は丸め頼みではなく整合性で守る。AIは万能ではないから、設計と運用で堅牢さを与える。これが今回の実践から得たいちばんの教訓です。
「AIを騙す」視点から仕組みを学ぶのは、とても実践的で刺激的な経験になります。
興味がある方は、ぜひ Hack The Box に挑戦してみてください。
👉 HackTheBoxの詳しい登録方法や、プランの違いはこちらをご確認ください。





